|
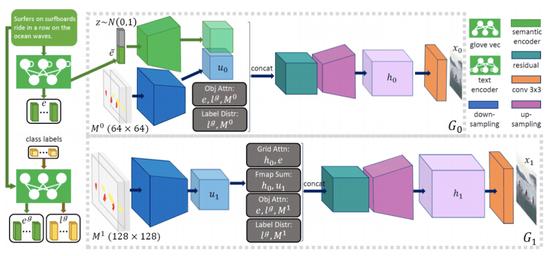
正如任何热心的读者都会做到的那样,人类只要精心挑选几个词,就能想象出复杂的场景。然而,人工智能系统在将文本描述转换成图片的任务上遇到了困难。现在,来自微软和JD人工智能实验室的研究人员提出了一种基于对象驱动的专注生成对抗网络(Obj-GAN)的新模型,该模型能够基于一个简短的短语或描述性文本句子生成相对复杂的场景。 Obj-GAN的生成器识别描述性单词和对象级信息,逐步细化合成图像,在图像细节和成分元素之间的关系方面改进了之前的前沿模型。 下面是运用不一样人工智能技术生成的真实图片和文本描述图像的比较。研究结果表明,随着描述的复杂化,Obj-GAN与其他GANs相比,越来越能够将文本转换成逼真的图像。 为了搞定这个问题,研究人员提出了一种新的目标驱动注意力机制,将图像生成分为两个步骤: 首先,研究人员运用seq2seq关心模型,将文本转换为语义布局,比如边框和形状。 然后,一个多级注意力图像生成器在上述布局的基础上创建一个低辨别率的图像,通过关心最相关的单词和预先生成的类标签,在不一样区域细化细节。研究人员还规划了分段和对象分类器,以确定合成的图像是否与文本描述和预先生成的布局匹配。 在他们的实验中,研究人员发现Obj-GAN在各种COCO基准测验任务上优于之前的SOTA方式,使Inception的分数提升了27%。
|
发表评论